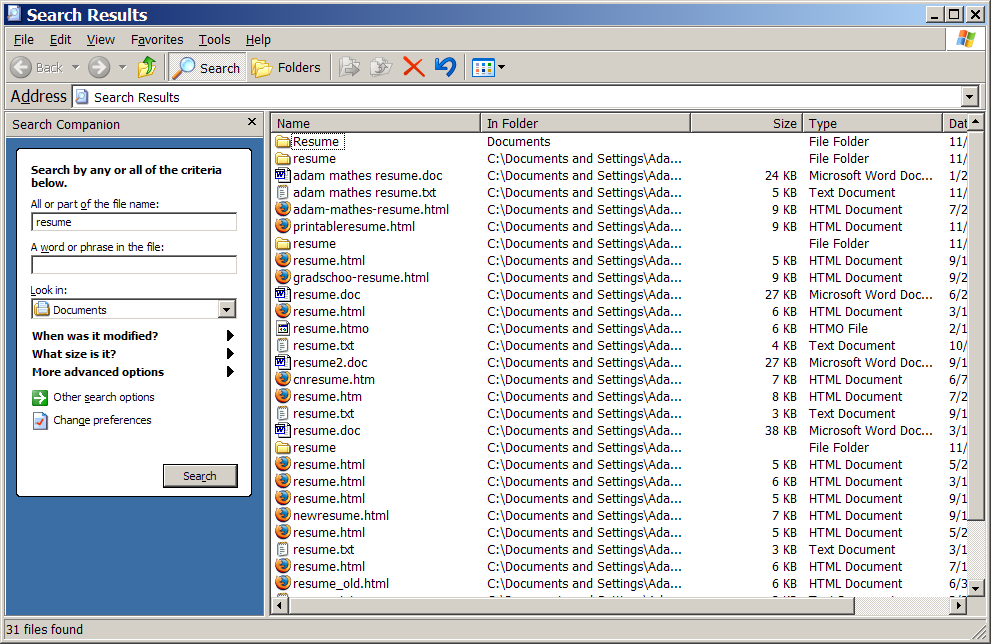
Windows XP Search Results
Adam Mathes
LIS350SE
May 2004
Search engines on the web often give people the experience that they have the entire world's knowledge at their fingertips. By indexing millions of documents on servers located around the world and returning ranked results of a user's queries almost instantly, systems like Google, Teoma, and Alltheweb make vast quantities of material more accessible in a manner that was unthinkable even a few years ago. Somewhat paradoxically, the general user experience of searching through the material located on a single user's desktop personal computer in 2004 is far worse. This paper will examine the problems of desktop search, evaluate some of the more recent offerings that attempt to deal with it, and make recommendations for further areas of study and development in this domain.
Despite some use of networked applications and the rise of the World Wide Web, the dominant computing paradigm in 2004 is still locally running applications producing documents and data stored locally on a single personal computer. The most popular computing platforms, Microsoft Windows, Apple's Macintosh OS X, and even the various Unix and Unix-like operating systems all rely on the same basic abstraction for file management. Even the term "file management" shows this bias - the operating system world is modeled after a giant filing cabinet of "files" that are placed within hierarchical "folders" (or directories.) Whether this fundamental abstraction helps or hinders the problems of desktop search is another issue to be evaluated.
Through the creation of files of content through applications, downloading of content from the Internet, or receiving content via email, this file system can become quite full of important content located throughout the system. Whether these files are carefully filed away in deeply nested hierarchical folders, or haphazardly filed away in a nearly flat system, at some point that data probably needs to be accessed again. It is at this point the problem of desktop search becomes apparent. In a system consisting of gigabytes and gigabytes of thousands or even millions of files, how does one locate a specific file?
If it is filed away "properly," that is, in a manner the user was conscious of and remembers, perhaps it will be easily located in that folder. But what if the user has put the file in a folder he can't remember? Or software automatically saved it somewhere he does not expect? Or the folder it is in contains over a hundred files, and the user can't remember the file's name? Or he knows the folder it is in, but can't remember where the folder is? There are many reasons to not be able to instantly remember the folder location of a file, especially if it was created months or even years earlier.
Ways in which software that employs indexing and searching to help with this problem is the domain examined here. This paper will focus on this search domain within Microsoft Windows XP because it is currently the dominant operating system by a large margin, but the general problems here likely apply to other systems.
The default search technology included with Microsoft Windows XP [ http://www.microsoft.com/windowsxp/ ] [1] is probably the first way a user would attempt to deal with the desktop search problem. While it is not completely ineffective, it does have serious limitations. I evaluated Windows XP Search in its advanced mode, not in its less powerful but default "wizard" mode.
Although all options are not immediately accessible, there are a large number of options to search files by:
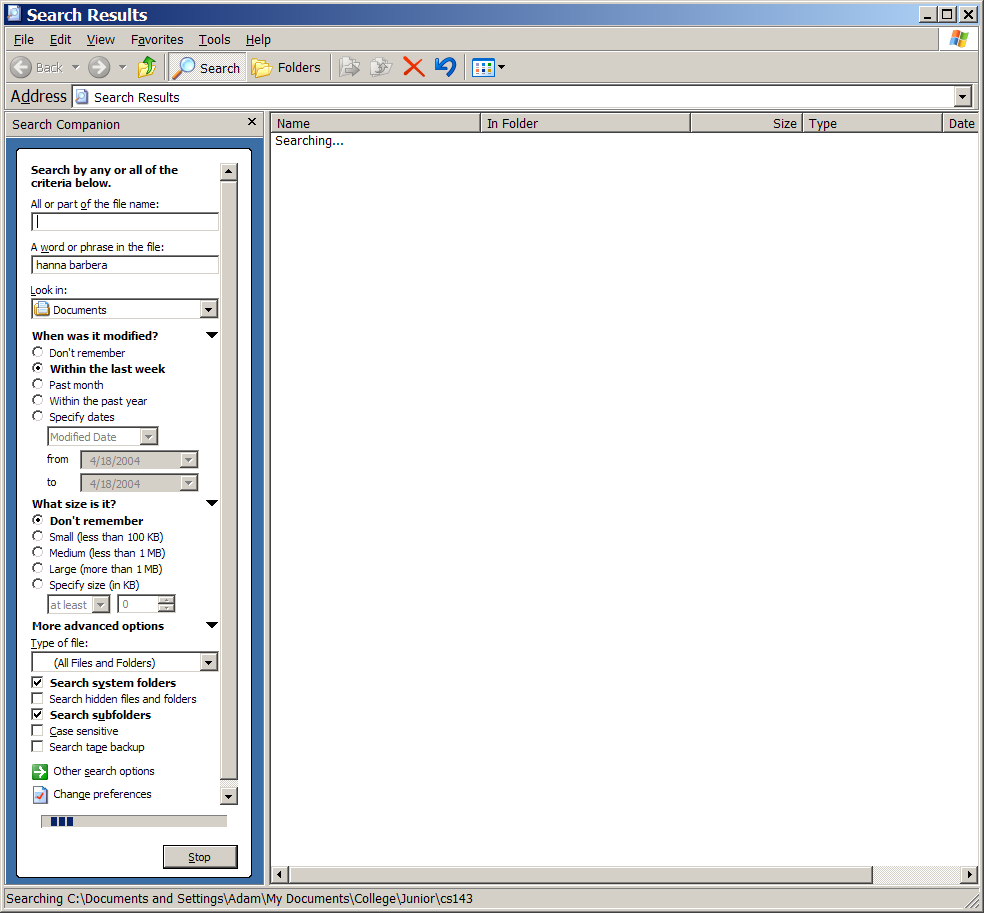
The Windows XP Advanced Search
Some serious limitations to these options are the inability to select multiple folders that are not nested for search, and the inability to select multiple file types for a search.
Windows XP search is accessible from the Windows Explorer, the basic file management interface, as well as from the "Start" menu. It is decently integrated into the general user experience of the operating system. Additionally, its results are returned in such a way that the results are usable as if they were in a regular Explorer window. This has the advantage of consistency.
Speed is a major issue. By default, neither file metadata or content is indexed in such a way that results are returned quickly. Although Windows XP includes something called "Indexing Service" that will index files for quick access, it is not enabled by default. It was not examined for the purposes of this paper since it is so seldom used or mentioned by normal users.
There is no meaningful ranking of the results. That is, although you can resort the results by the common file system metadata: name, folder location, file type, and date modified, results seemed to be returned simply in the order they are found as Windows XP Search linearly searches through files and folders.
Windows XP Search Results
While the results are returned in a familiar interface, the lack of any good preview of the content makes it difficult to know which results are pertinent, usually forcing the user to open the file up in its native application to determine what it actually is. There is much room for improvement in the feedback to the user regarding the results.
Finally, Windows XP search can only search the content of text files it understands. To search through things like your email, even if you are using Microsoft's own Outlook product, the user has to use a different search tool. It also has no facility for doing content based searching of media files.
HotBot [ http://www.hotbot.com/ ] [2], considered one of the top search engines only a few years ago, now has a fraction of its former share of the search engine market. Recently, however, they released HotBot Desktop [ http://www.hotbot.com/tools/desktop/ ] [3] which allows a user to search the web as well as the local file system. Version 1.0.1035 was used for this report.
Installation was actually rather difficult for me since I do not use Internet Explorer, and had its security settings very strict. Installation required altering my security settings. After initial installation, I changed the settings to index the folder which had my documents in it.
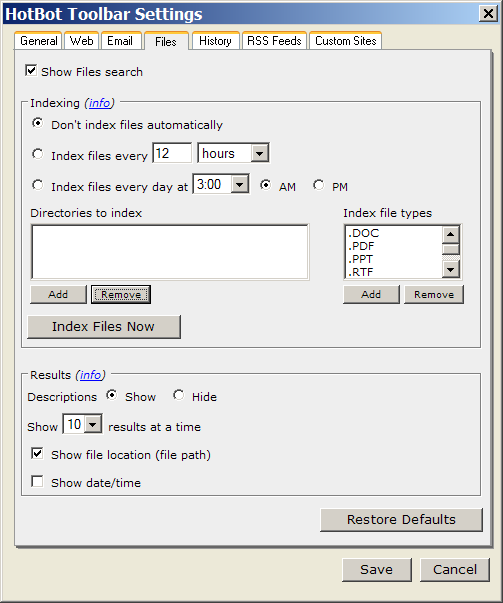
The HotBot Desktop settings dialog with default options
While indexing, it's very difficult to see if it's actually doing anything. A taskbar icon changes color slightly, and hovering over it reveals the text "indexing files." There's no apparent progress indicator. User feedback on what the application is doing is particularly bad.
Additionally, the system apparently doesn't allow you to search partially indexed directories, as my attempts to search while it was still indexing yielded no results for queries I knew should have results. After waiting half an hour and still getting no results, I uninstalled the program in an attempt to clean out the index and try a smaller sample directory. However, uninstalling doesn't fully uninstall the program - it leaves indexes and data, exactly the material I wanted to remove. After a bit of snooping, I managed to locate and delete the indexes, but already I was very displeased with the program. If after half an hour with no other programs on my computer it could not index a few hundred megabytes of documents, it hardly seems like a robust solution.
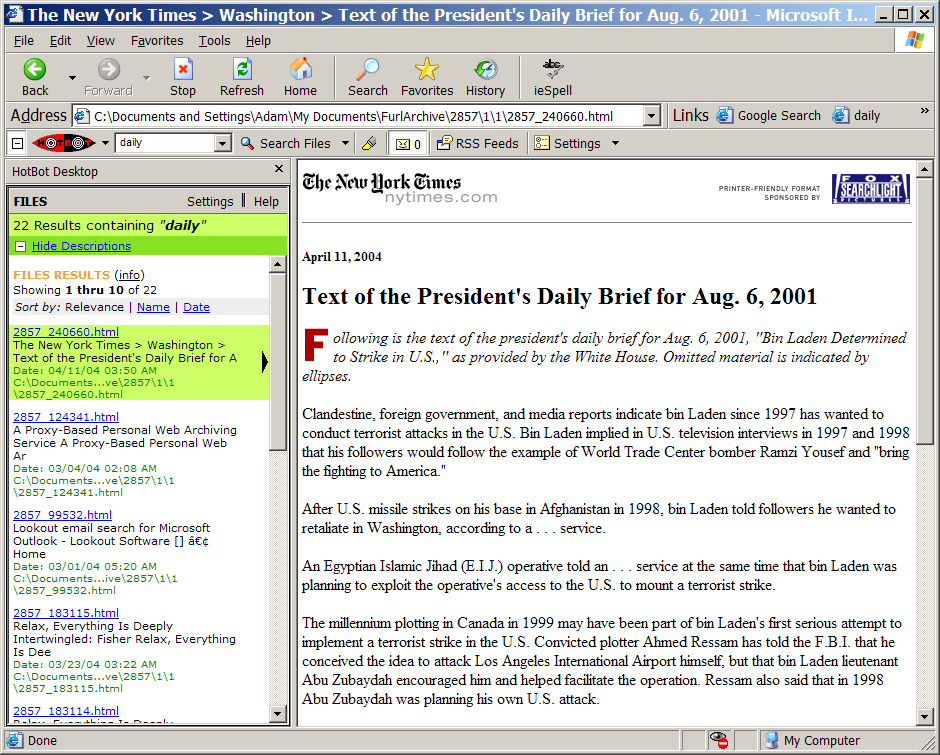
Results returned from a search in HotBot Desktop
HotBot Desktop is only usable with Microsoft Internet Explorer. It adds a toolbar to Internet Explorer. Search is by entering text in a text box on that search bar. Results are displayed in a sidebar within Internet Explorer. There are no options to immediately narrow your search.
X1 search [ http://www.x1.com/ ] [4] is an interesting product from a company of the same name that provides facilities to index and search local content, including files and email. It's being developed by some of the people that worked on Lotus Magellan, a similar product from 1989. [ http://www.x1.com/about_us/ ] [5]
The X1 indexer indexing content
X1's interface consists primarily of two panes side by side, and a set of search tabs above. (See figure) The left pane is used to narrow a search or resort the results by metadata like filename, type, date, and size, as well as display a list of results. The right pane is used to view a single result. This allows a sort of counter-clockwise workflow for searching, refining searches, and viewing.
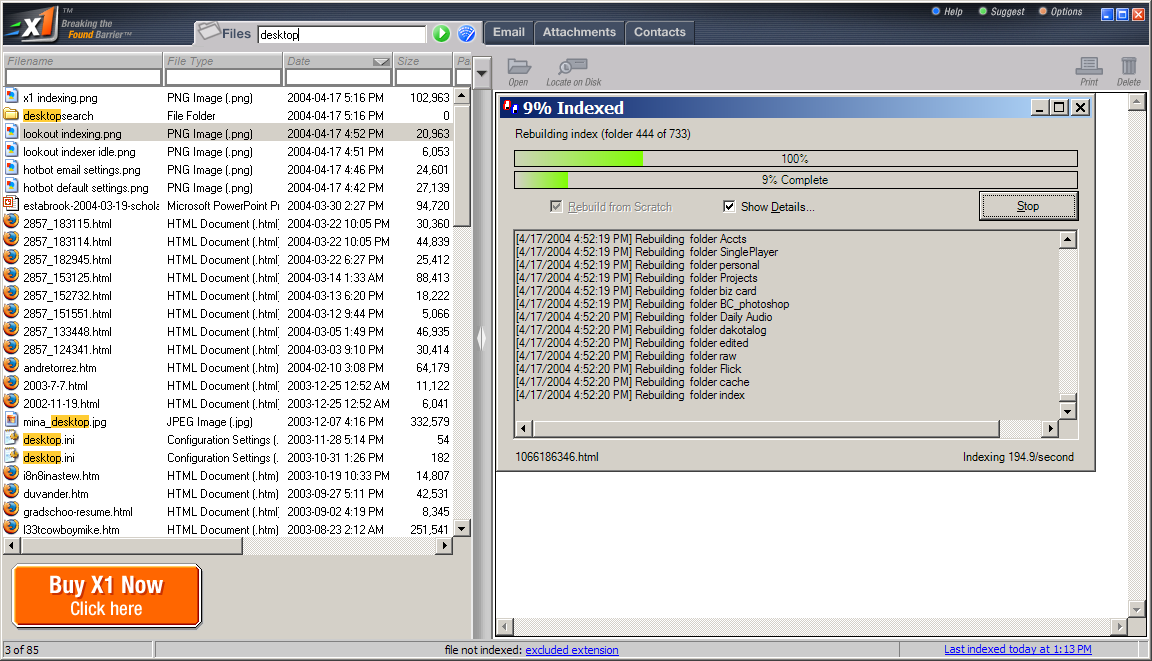
Results from a search using X1
X1 offers the ability to search files, email, email attachments, and contacts. Each of these has a "tab" and the left search and results pane changes on selection to reflect the metadata that is searchable for that type of search. Results are displayed not just instantly, but as you type. All possible results are shown initially and with each keystroke the results list decreases to those that match the partially constructed query. This is very nice and provides constant feedback to the user when it works properly, however, sometimes the application seemed to slow down a bit during some queries. It might be nice to be able to toggle the results as you type feature on and off. The results list is also highlighted in real time, showing results that have metadata that matches the query. The right view pane also highlights the search terms in text-based results when a result is selected from the left pane.
Of the programs examined, X1 showed the most promise, although it still seems a bit unstable. HotBot Deskbar, however, has some intriguing features, although its overall user experience was poor. Both programs offer significant advantages over the default Windows XP search in terms of speed due to their use of indexing.
None of these programs does anything particularly interesting in the ranking of the results. Although not rigorously tested, it seemed apparent that what little ranking of results was done was based on traditional word frequency.
A more complicated metric that a well designed operating system might be able to measure is to correlate corresponding documents by use. That is if you had X documents open during similar timeframes, those X documents are probably related. Assuming you are currently using one of those X documents, the other documents in the set could be ranked higher in their return. You can approximate this by setting modification dates or ordering the results by modification or creation date, but it's not quite the same idea.
This metric brings about two points. First, the context of the search - what documents and text you have open or have recently modified - could help immensely, and since this is search done on a local computer that information could be accessible. Second, it points out that a text-based keyword search may not be the whole answer. A content-based information retrieval system that allows you to construct search queries based on the kind of content you're searching for could be an important area for research. This isn't the best example, but rather than just searching for a company name in your email to find correspondence with members of that company, if you have one email from that company the fact that all email from that company will be from the same domain name is something your search tool could notice. It might rank email to and from that specific person as most relevant, email to and from that company as also relevant. When you think of your documents and content as query statements, interesting possibilities open up.
When the domain switches from email to media - like music or images - the possibilities for content-based image retrieval seem even more interesting. Especially considering the relatively impoverished state of metadata, text-based searching for media content on the desktop is extremely difficult.
Another way to look at the problem entirely is that the current filesystem is flawed. While it may be convenient for operating systems developers to think of files and directories, at the user level perhaps there should be even more abstraction away from the filesystem. Some examples of this includes Apple's work with iPhoto [ http://www.apple.com/ilife/iphoto/ ] [6] and iTunes [ http://www.apple.com/itunes/ ] [7] for digital photographs and music. Adobe Photoshop Album [ http://www.adobe.com/products/photoshopalbum/ ] [8] is another. All of these add important, relevant metadata to the content items and provide instant searches, queries, and "virtual folders" based on them. Adobe Photoshop Album also supports querying by image content.
A look at some of the most recent offerings in the desktop search space shows there is still much work to be done. Interface issues, a problem throughout the software industry, are one part of the problem. The two programs here some almost more at the "proof of concept" stage. They get some of the basic technical necessitates down for indexing and querying, but that is not enough. The reason Google and web search engines are so successful is that they provide clear feedback on the results, and rank the results in a meaningful, important manner.
There is clearly much work to be done in leveraging implicit information in the operating system to improve the results of local searches and their rankings.
In the end, this may be a problem that is not well solved by an add-on indexing and searching program, and needs to be more tightly integrated into the operating system. If Amazon.com can recommend related books while you're shopping, why can't your computer recommend related documents as you're working?